This is the third post in the TD-MPC-Glass series. The first post introduced the JAX TD-MPC2 implementation and the Phase 1b Glass integration. The second post covered Iterations 2-7 and ended with the K_UPDATE hypothesis. This post covers Iterations 8-9: what we learned from MPPI-vs-policy diagnostics, why several stability losses missed, why the best current recipe is early Glass followed by a handoff back to TD-MPC2, and where the current 5-seed confidence-interval comparison stands.
Previous posts:
- TD-MPC-Glass: From Scratch to Phase 2 on HopperHop
- TD-MPC-Glass Iterations 2-7: Basin Lottery, Glass Internals, and the K_UPDATE Hypothesis
Snapshot time for the tables below: 2026-05-27 07:34 UTC.
1. The short version#
The strongest current hypothesis is:
Glass is useful as an early latent-shaping pressure, but it should not keep pushing the representation forever. On HopperHop, the current best recipe is Phase1b-style Glass with K_UPDATE=128, exploration shortened to 25k steps, and Glass decayed away around 1M environment steps.
The current best family is phasei9r, which turns Glass off at 1M steps.
| Family | Design | Countable runs | Mean best return | 95% CI | G1 hits |
|---|---|---|---|---|---|
phasei9r | Phase1b Glass, off at 1M | 5 | 523.9 | [426.3, 621.4] | 4/5 |
phasei9t | Phase1b Glass, off at 1.5M | 3 | 469.9 | [164.2, 775.6] | 2/3 |
phasei9q | Phase1b + temp 0.01, off at 2M | 7 | 435.8 | [314.7, 556.9] | 3/7 |
phasei10c | clean rerun of off at 1M | 4 | 316.5 | [176.2, 456.8] | 0/4 |
| TD-MPC2 K256 | internal TD-MPC2, ~official update rate | 3 | 389.3 | [82.7, 695.9] | 1/3 |
| TD-MPC2 K128 | internal TD-MPC2, half update rate | 3 | 304.8 | [247.4, 362.2] | 0/3 |
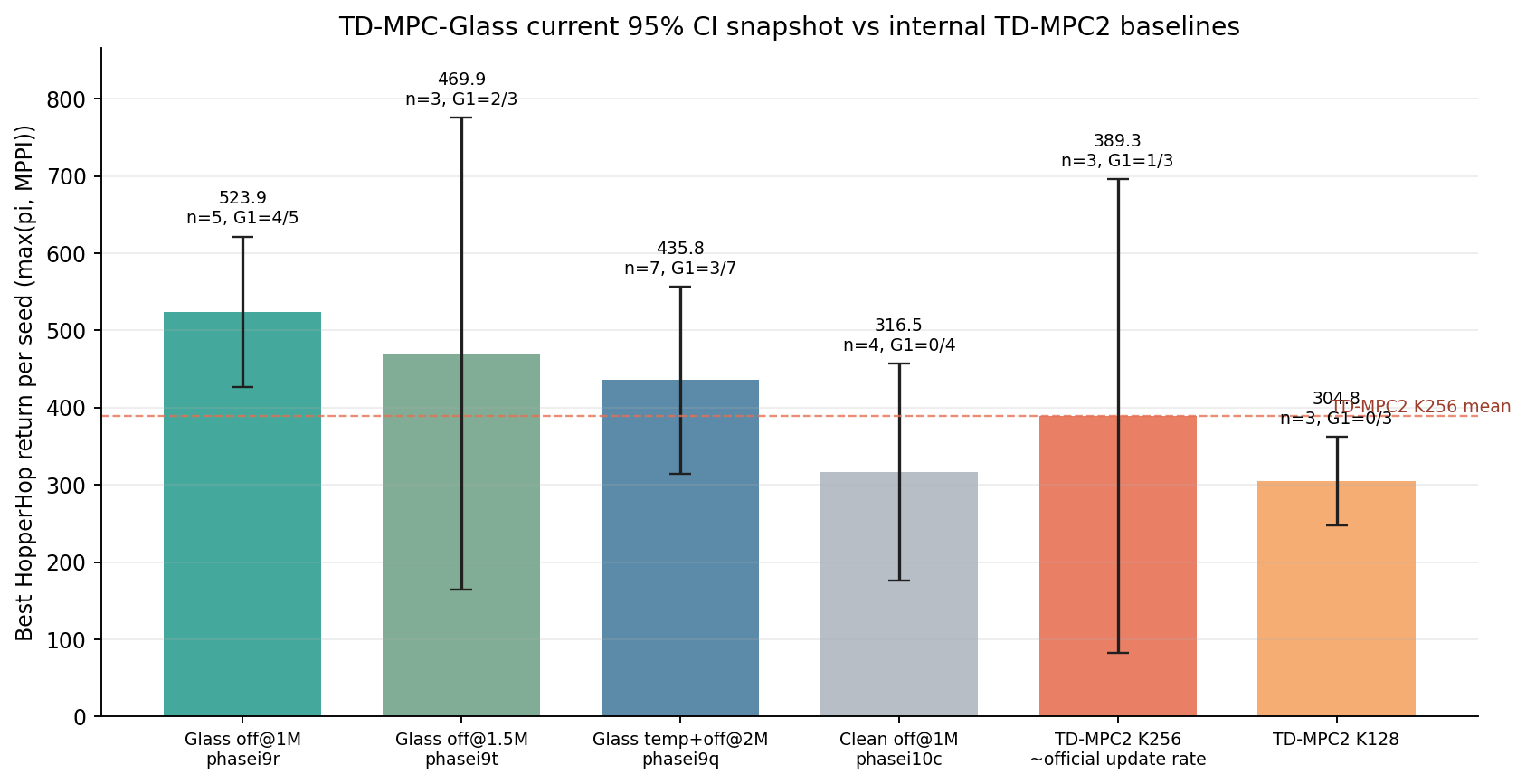
Interpretation:
phasei9rcurrently beats the internal TD-MPC2 K256 mean by +134.6 return points.- Its lower 95% CI bound is also above the TD-MPC2 K256 mean.
- This is still not a final statistical claim because TD-MPC2 K256 only has three countable seeds here and its own CI is wide.
- The clean
phasei10crerun is not yet confirmingphasei9r; it is early and currently weak. That is the main reason I still call this a working hypothesis rather than a solved result.
The practical conclusion: the next fair comparison is not more new losses. It is a disciplined 5-seed completion of the promising handoff schedules.
2. What changed since Iterations 2-7#
The earlier phase sequence taught us three things:
- Glass can create useful latent structure, but strong structural pressure can also trap the agent in low-return basins.
- HopperHop has a “basin lottery”: some seeds discover a viable hop, others kneel, crawl, or learn short-lived recovery behaviours.
- The original K_UPDATE=64 setting was likely undertraining relative to the official TD-MPC2 update rate.
Iteration 8 and 9 were a response to those three facts. We stopped treating Glass as a permanent auxiliary objective and started asking a narrower question:
Can Glass improve basin entry early, then leave the policy/dynamics learner alone once TD-MPC2 has enough reward signal?
This led to the off-schedule experiments:
phasei9r: Glass off at 1M.phasei9t: Glass off at 1.5M.phasei9q: temp-stability + Glass off at 2M.phasei10c: clean off-at-1M rerun away from interrupted and unstable boxes.
The best answer so far is phasei9r.
3. The diagnostic that changed the direction: MPPI is not always better#
The original evaluation habit was to report the best MPPI reward. That made sense because TD-MPC2 is a planner: at evaluation time, MPPI should improve over the actor by searching action sequences in the learned latent model.
But the result CSVs showed a recurring problem:
In some runs, MPPI reward is worse than policy reward.
That is not just noise. It means the learned model and value head can mis-rank action sequences. If the actor already learned a good gait but MPPI evaluates latent rollouts poorly, planning can damage the policy at test time.
For this reason, we switched most summaries to:
$$ \text{best-any} = \max(\text{best-pi}, \text{best-MPPI}) $$This is not a trick to inflate numbers. It is a diagnostic split:
pitells us whether the actor learned a useful closed-loop behaviour.MPPItells us whether latent planning can exploit the learned model.- The gap tells us whether the model/planner is helping or hurting.
This matters for Glass because Glass touches the representation used by both the actor and the planner. A structural entropy objective can improve the actor basin while still making the planner overconfident in the wrong latent transitions. That is exactly the kind of failure a single MPPI-only scalar can hide.
4. Iteration 8: stability losses were not the answer#
Iteration 8 tested the idea that Glass needed smoother or more stable cluster assignments. The motivation was reasonable: if the assignment graph flickers, structural entropy may push on noise rather than behavioural phases.
The main probes were:
- stronger temporal stability;
- MPPI-gated distillation;
- auto-restart for bad early basins;
- Phase1b reruns at longer budgets;
- checks for checkpoint and infrastructure failures.
The outcome was mixed.
4.1 Temp-stability helped individual seeds but did not solve robustness#
The phaseg2 temp-stability run reached a high max of about 570, but it did not
produce the desired 5/5 profile. This repeated an earlier pattern: one lucky
seed can be good, but the weak seeds remain weak.
That matters because the target is not “find one video that hops.” The target is G1:
| Goal | Criterion |
|---|---|
| G1 | 5/5 HopperHop seeds reach best return above 500 |
Temp-stability did not get us there.
4.2 MPPI-gated distillation failed operationally first#
The MPPI-gated distillation idea was:
Distill from MPPI only when MPPI is clearly better than the actor.
This was motivated by the pi-vs-MPPI gap. In principle it avoids forcing the actor to imitate bad planner choices. In practice the first runs failed quickly because the initial implementation and environment assumptions were not smoke-tested well enough. That made it a bad iteration target at the time: we needed reliable evidence faster than we needed a more complex branch.
The lesson was operational: every new mechanism should pass a smoke test before entering the fleet queue, and tasks should go through the central queue rather than direct local scripts.
4.3 Auto-restart can rescue some runs, but it is not the Glass mechanism#
Auto-restart produced a high maximum, but it did not explain the main Glass effect. It is a useful queue/tooling idea: if a run clearly falls into a bad basin early, restart it. But as a scientific result it is orthogonal to the structural entropy question.
For the Glass paper path, auto-restart is best treated as an engineering control, not the main algorithmic contribution.
5. Iteration 9: the handoff hypothesis#
Iteration 9 narrowed the design space.
All of the strongest variants share the same base recipe:
| Component | Setting |
|---|---|
| Algorithm | TD-MPC-Glass |
| Task | HopperHop |
| K_UPDATE | 128 |
| MPPI samples | 2048 |
| Exploration | shortened to 25k steps |
| Glass warmup | 100k steps |
| Prototype temperature | 0.7 |
| Temp-stability coefficient | 0 or 0.01 depending on phase |
| Assign-logit init scale | 0.5 |
| Stopgrad graph | true |
| Latent smooth | 0 |
| Main variable | when Glass decays away |
5.1 Two different “temps”#
There are two temperature-like knobs in these phases, and it is easy to mix them up.
Prototype temperature is the softmax temperature used when a latent \(z_t\) is assigned to the \(N=16\) Glass prototypes. The assignment is:
$$ c_{t,n} = \frac{\exp(\operatorname{sim}(z_t,\mu_n) / \tau_p)} {\sum_j \exp(\operatorname{sim}(z_t,\mu_j) / \tau_p)} $$where \(\tau_p\) is the prototype temperature. Lower \(\tau_p\) makes the assignment sharper: one prototype dominates. Higher \(\tau_p\) makes the assignment softer: several prototypes share probability mass. In these handoff phases we use \(\tau_p=0.7\), sharper than the earlier default of 1.0, because the useful signal seemed to come from a clearer early basin partition.
Temp-stability, despite the name, is not this softmax temperature. It is an extra loss coefficient that penalizes assignment changes over adjacent latent states. A simplified form is:
$$ \mathcal{L}_{\text{temp-stability}} = \|c_t - c_{t+1}\|_2^2 $$When a phase says temp 0.01, it means the coefficient on this stability loss
is 0.01. It asks Glass to make nearby rollout states keep similar prototype
assignments. That can reduce cluster flicker, but it can also smooth over
important contact transitions. This is why phasei9q is interesting but not
obviously superior: it keeps weak assignment-stability pressure until 2M steps,
yet still shows high variance across seeds.
The handoff experiments are therefore testing two separate claims:
| Knob | What it controls | Current read |
|---|---|---|
| Prototype temperature \(\tau_p=0.7\) | sharpness of latent-to-prototype assignment | useful in the Phase1b handoff recipe |
| Temp-stability coefficient 0.01 | penalty on assignment flicker over time | sometimes helps high seeds, not enough for robustness |
5.2 Handoff schedules#
The tested handoff schedules:
| Phase | Handoff schedule | Motivation |
|---|---|---|
phasei9r | Glass off at 1M | Shape the early basin, then let TD-MPC2 consolidate. |
phasei9t | Glass off at 1.5M | Test a midpoint handoff. |
phasei9q | temp 0.01 + off at 2M | Keep weak assignment stability pressure longer. |
phasei10c | clean off at 1M rerun | Re-test the best hypothesis under cleaner queue conditions. |
The motivation is now quite concrete:
- Early in training, the agent has little reward signal and many bad basins. Glass can bias the latent toward coherent behavioural regions.
- Later in training, TD-MPC2 needs a representation tuned for reward, Q-values, dynamics rollouts, and the actor. A permanent structural objective may keep moving the latent in a direction that no longer helps control.
- The best policy videos from earlier iterations did not require a rich 4-phase gait cluster. The best behaviour often looked more like a simple “bad basin vs hopping basin” separation. That makes early basin shaping more plausible than lifelong gait-phase supervision.
So the current design philosophy is:
Use Glass to help the agent enter the right part of representation space, then anneal it away before it fights TD-MPC2’s control objective.
6. Current results#
The plot in the introduction is generated from the current dashboard CSVs. The metric is best return per seed:
$$ \max(\text{best-pi}, \text{best-MPPI}) $$Runs are counted once they reach at least 4M steps, except early G1 runs \(\ge 500\), which are included as useful high-signal evidence. This is the same rule used by the live dashboard. Failed logs and partial metrics are kept, but they are labelled as partial evidence when making final claims.
6.1 Snapshot table#
| Phase | Values used | Mean | 95% CI | G1 |
|---|---|---|---|---|
phasei9r | 389.0, 595.3, 540.3, 551.7, 543.1 | 523.9 | [426.3, 621.4] | 4/5 |
phasei9t | 558.6, 521.7, 329.4 | 469.9 | [164.2, 775.6] | 2/3 |
phasei9q | 267.6, 570.3, 347.5, 521.0, 442.6, 593.8, 307.9 | 435.8 | [314.7, 556.9] | 3/7 |
phasei10c | 325.4, 436.9, 238.0, 265.6 | 316.5 | [176.2, 456.8] | 0/4 |
| TD-MPC2 K256 | 331.4, 531.0, 305.5 | 389.3 | [82.7, 695.9] | 1/3 |
| TD-MPC2 K128 | 288.4, 331.2, 294.8 | 304.8 | [247.4, 362.2] | 0/3 |
There are two ways to read this table.
The optimistic read:
phasei9ris the first Glass family in this iteration window with a 5-run mean clearly above our internal TD-MPC2 means.- It has 4/5 G1 hits.
- Its lower 95% CI bound is above the TD-MPC2 K256 mean.
The conservative read:
- TD-MPC2 K256 only has 3 countable seeds in this snapshot.
- Its CI is extremely wide.
- The clean
phasei10crerun is not yet reproducing the same result. - Some
phasei9revidence comes from the messy fast-iteration period, not a single pristine 5-seed launch.
Both reads are true. This is promising enough to focus the queue, but not enough to claim the algorithm is solved.
6.2 Why phasei10c matters#
phasei10c is the clean rerun of the off-at-1M idea:
- same core handoff recipe;
- fixed queue discipline;
- no destroyed-box seeds;
- standard 10M budget;
- seeds 1-5 launched as a fair comparison set.
Right now it is weak: mean 316.5, no G1 seeds in the current snapshot. But this
is exactly why reruns exist. phasei9r says the idea can work. phasei10c tests
whether it works cleanly enough to be a publishable claim.
If phasei10c stays weak after all five runs mature, the conclusion changes:
The off-at-1M handoff is a real lead, but it is sensitive to implementation details, hardware interruptions, or seed-selection history. We should not present it as a robust method yet.
If phasei10c recovers and reaches the same range as phasei9r, the conclusion
becomes much stronger:
Early Glass handoff is a reproducible way to improve HopperHop reliability over our TD-MPC2 baseline.
7. Queue discipline became part of the science#
One uncomfortable lesson from this project is that experiment operations can change scientific interpretation.
Several early “bad algorithm” events were actually:
- full disks from large checkpoints;
- destroyed or budget-killed Vast instances;
- CUDA/JAX environment failures;
- low
pids.maxcontainers causing PJRT pthread creation failures; - direct local scripts bypassing the queue;
- duplicate auto-promotions after partial failures;
- counting interrupted runs as if they were completed seeds.
Those are not minor annoyances. They change phase means, G1 denominators, and which idea looks promising.
The current queue rules are therefore stricter:
| Rule | Reason |
|---|---|
| One seed per queue task | Easier retry, accounting, and worker assignment. |
| No full-state checkpoint by default | Avoid disk-full failure loops. |
| Count interrupted runs below 4M only if they already exceed 500 | Preserve strong signal without polluting weak means. |
| Cap auto-promotion at 5 seeds for CI phases | The current target is a fair 5-seed comparison, not unbounded exploration. |
| Record worker failures in the queue | A destroyed box should not silently become a bad seed. |
| Prefer central queue launches | Direct scripts make reproducibility and ETA worse. |
This is why the post reports both the exciting result and the caveat. The result is real enough to steer the next experiment. The evidence is not clean enough to end the project.
8. What each current promising phase is testing#
phasei9r: Glass off at 1M#
This is the current leader. It asks whether Glass should act as an early representation prior rather than a permanent loss.
Current snapshot:
- mean best: 523.9;
- G1: 4/5;
- best seed: 595.3;
- main caveat: mixed fast-iteration provenance.
This is the phase to beat.
phasei9t: Glass off at 1.5M#
This tests whether the 1M handoff is too early. The early evidence is good but still sparse:
- mean best: 469.9 over 3 countable runs;
- 2/3 G1;
- very wide CI because \(n=3\).
If seed 5 and the remaining fill runs mature well, this could become the more robust midpoint schedule.
phasei9q: temp-stability plus off at 2M#
This keeps assignment-stability pressure longer. It has several high seeds, but also several weak ones:
- mean best: 435.8;
- G1: 3/7;
- larger variance than we want.
The likely interpretation is that stability pressure helps some seeds but does not remove the basin lottery.
phasei10c: clean off-at-1M confirmation#
This is the most important negative/positive control right now. It is the clean
version of the best hypothesis. It currently looks weak, but it is still the
run that will decide how much confidence to place in phasei9r.
9. What I think is happening mechanistically#
The Glass objective builds a transition graph over prototype assignments and minimises a two-dimensional structural entropy objective. Intuitively, it encourages the latent dynamics to form a small number of coherent behavioural regions.
Early in HopperHop training, that pressure is useful because the agent has not yet discovered a stable reward-producing gait. The structural objective can make the latent less chaotic and make early behavioural modes more separable.
Later, the same pressure may become harmful:
- it can keep prototypes adapting after the actor already found a useful behaviour;
- it can make MPPI over-trust a simplified transition graph;
- it can bias the representation toward cluster coherence instead of Q-value precision;
- it can fight the actor’s need for fine control around contact dynamics.
That explains the handoff pattern:
$$ \mathcal{L}(t) = \mathcal{L}_{\text{TD-MPC2}}
- \lambda_{\mathrm{Glass}}(t)\mathcal{L}{\mathrm{Glass}}, \qquad \lambda{\mathrm{Glass}}(t) \to 0 ;;\text{around 1M steps}. $$
The goal is not to make a perfect gait-state clustering model. The goal is to use structural entropy to shape early representation learning, then get out of the way.
10. What happens next#
The queue is now focused on fair 5-seed comparisons:
- finish
phasei9rreplacement/fill seeds; - finish
phasei9tseeds 1 and 5; - finish
phasei9qreplacement seeds 1 and 5; - finish the clean
phasei10c5-seed rerun; - recompute countable-only 95% CI tables;
- only then decide whether to design a new loss.
The current ETA from the dashboard is roughly 2026-05-27 22:16 UTC for the active promising-phase queue, assuming no Vast failures.
The next decision rule is simple:
| Outcome | Next action |
|---|---|
phasei10c matches phasei9r | Promote early Glass handoff as the main method and render diagnostics/videos. |
phasei9t beats phasei9r | Move handoff later, around 1.5M. |
phasei9q improves robustness | Keep a weak temp-stability term, but only until 2M. |
| all clean fills regress | Treat phasei9r as a useful but non-robust lead and return to mechanism design. |
10.1 G2 ideas: pushing the ceiling past 600#
G1 is the reliability goal: every seed should reach 500. G2 is the ceiling goal: at least one benchmark-fair seed should clear 600 without reward shaping or environment edits. We have seen that the physical ceiling exists, but not yet in a clean Glass setting.
The next G2 probes should be different from the G1 probes. G1 asks how to avoid bad basins; G2 asks how to exploit a good basin once one appears. Candidate directions:
| Direction | Why it might raise G2 | Risk |
|---|---|---|
| Planner/actor arbitration | Use MPPI only when it beats the actor on recent evals; fall back to pi otherwise. | Can overfit to noisy evals if the switch is too reactive. |
| Larger MPPI only after basin entry | Keep cheap planning early, then raise samples or horizon once reward crosses 400. | More compute and possible model exploitation. |
| Checkpoint continuation from high-return seeds | Resume from 500+ checkpoints with lower Glass weight and tuned actor learning. | Not a fair-from-scratch method unless reported separately. |
| Late actor-only consolidation | After Glass off, run a short actor/Q consolidation stage with planning disabled for eval. | May improve pi while hurting MPPI. |
| Planner calibration loss | Penalize cases where MPPI predicts improvement but realized return is worse than pi. | Requires careful logging of planned vs realized outcomes. |
| Adaptive handoff time | Turn Glass off when diagnostics show stable gait entry rather than at a fixed 1M/1.5M. | Adds another controller and can hide seed-specific tuning. |
| Prototype-temperature anneal | Start sharp for basin separation, then soften before Glass turns off. | Too much softness may erase the useful early partition. |
| Gait-phase diagnostic gating | Use rollout videos/cluster traces to detect “hopping mode” and trigger exploitation settings. | Video-derived rules are expensive and may not generalize. |
My current preference for G2 is:
- finish the G1 5-seed CI queue first;
- take the best countable
phasei9r/phasei9tcheckpoints; - run a clearly labelled continuation study that tests planner/actor arbitration and late actor-only consolidation;
- only if that works, convert the continuation recipe into a from-scratch schedule.
This keeps the claims separated: G1 is about reliable learning from scratch; G2 is about extracting the maximum return once a good basin is found.
The strongest current statement is therefore:
We have a credible lead: early Glass with off-at-1M currently beats our internal TD-MPC2 mean and has 4/5 G1 hits in the countable snapshot. The clean rerun is still in progress and is the deciding test.
That is the right level of confidence for now.