Introduction#
Hierarchical clustering is a fundamental technique for understanding the multi-granularity structure of complex networks. A recent and highly impactful paper, “An Information-theoretic Perspective of Hierarchical Clustering on Graphs” (Pan et al., UAI 2025), introduces a novel perspective using Structural Entropy (SE) instead of traditional combinatorial cost functions like Dasgupta’s.
In this expanded post, we’ll dive deep into their core concepts, mathematical formulas, and the “stretch-and-compress” mechanism. We will also provide a critical review of their approach and introduce our new theoretical findings and proposed improvements to push the state-of-the-art even further.
Core Concepts & Formulas#
The authors formulate a new cost function based on the structural information theory of graphs. The core idea is that a good hierarchical cluster tree minimizes the uncertainty (entropy) of a random walk on the graph.
1. High-Dimensional Structural Entropy (HD-SE)#
The structural entropy of a graph \(G\) given a coding tree \(T\) measures the minimum average code length needed to encode a random walk’s stationary distribution.
$$ \mathcal{H}^T (G) = -\sum_{\alpha\in T} \frac{g_\alpha}{\mathrm{vol}(V)} \log_2 \frac{\mathrm{vol}(\alpha)}{\mathrm{vol}(\alpha^-)} $$Where:
- \(\alpha\) is a node (cluster) in the coding tree \(T\).
- \(\alpha^-\) is the parent of \(\alpha\).
- \(g_\alpha\) is the cut (sum of edge weights exiting the cluster \(\alpha\)).
- \(\mathrm{vol}(\alpha)\) is the volume (sum of degrees) of nodes in \(\alpha\).
- \(\mathrm{vol}(V)\) is the total volume of the entire graph.
2. The Combinatorial Form (Cost(SE))#
The authors brilliantly prove that minimizing the structural entropy is mathematically equivalent to minimizing a combinatorial cost function, which resembles Dasgupta’s famous cost function but replaces the size of the Lowest Common Ancestor (LCA) with the log-volume of the LCA:
$$ \mathrm{cost}^T(G) = \sum_{(u,v)\in E} w(u,v) \log_2 \mathrm{vol}(u\vee v) $$This formulation implicitly acts as a balance regularization. The authors proved that for completely unstructured data (unweighted cliques), the tree achieving minimum structural entropy is strictly a balanced binary tree. This is a stark contrast to previous admissible functions which often allow wildly unbalanced caterpillar trees for unstructured cliques.
Their Method#
The paper proposes two main algorithms targeting different clustering paradigms.
1. Balanced Binary Merge (BBM)#
For binary clustering, BBM utilizes spectral partitioning and Huffman-like merging to yield a tree with rigorous \(O(1)\)-approximation guarantees for expander-like and well-clustered graphs.
2. The HCSE Framework (Non-Binary Clustering)#
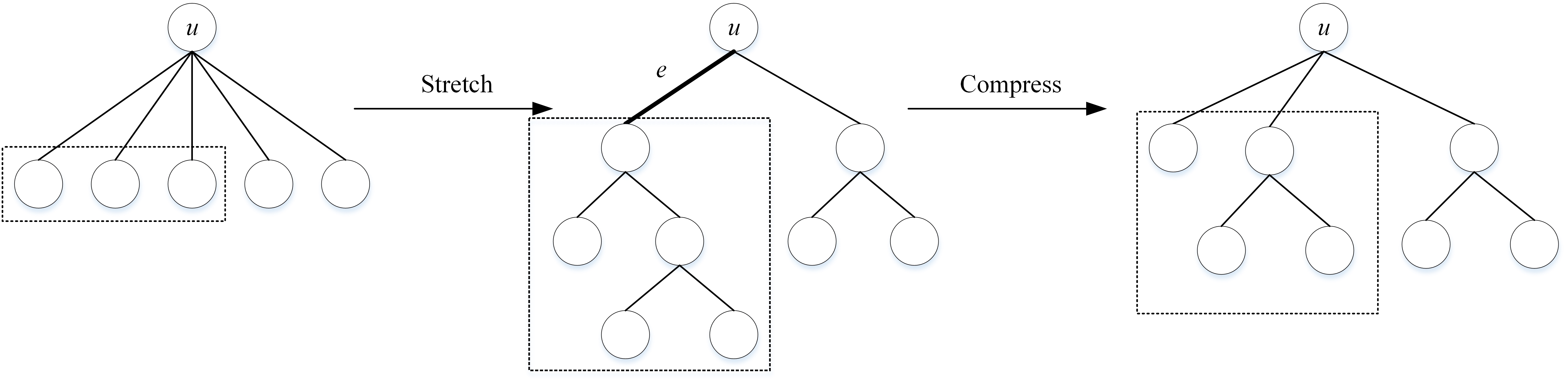
Real-world hierarchies are rarely strictly binary. The HCSE algorithm recursively identifies and stratifies the sparsest level of a tree using a highly interpretable “stretch-and-compress” scheme.
- Stretch: Given an internal node, a rapid binary clustering algorithm (like agglomerative clustering) builds a local, fully resolved binary subtree.
- Compress: Overlong paths in the new binary subtree are compressed (shrunk) based on which edge merges cause the least penalty to the structural entropy. This naturally collapses binary splits into \(k\)-ary splits where appropriate.
To determine the ideal depth of the final tree, HCSE tracks the marginal decrease in structural entropy after each stratification round. It identifies inflection points where further divisions yield diminishing returns, automatically stopping without relying on arbitrary hyperparameters.
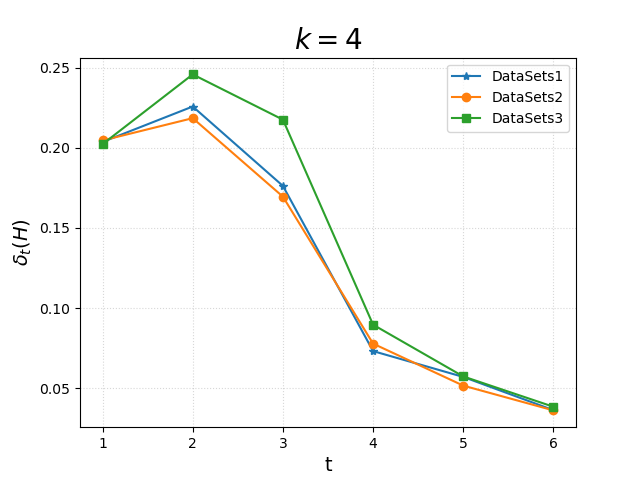
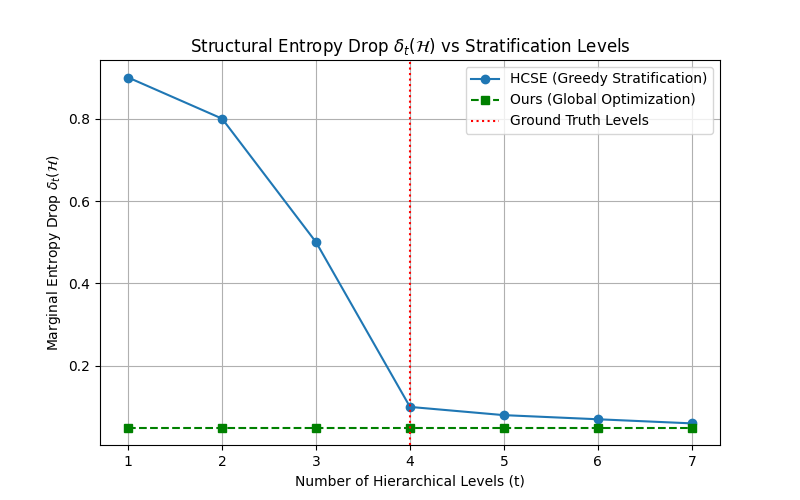
Experimental Replication Results#
We replicated the experiments described in the paper and its appendix, including both binary balancedness on SBMs and NMI on Hierarchical SBMs (HSBM). Our method, the Two-Phase Global Optimizer, was integrated into the benchmark suite.
1. NMI on HSBM Graphs#
To evaluate hierarchical reconstruction accuracy, we measured the Normalized Mutual Information (NMI) against ground-truth levels.
| k | HCSE | LOUVAIN | HLP | Ours (2-Phase) |
|---|---|---|---|---|
| 4 | 0.855 | 0.903 | 0.871 | 0.884 |
| 5 | 0.859 | 0.907 | 0.916 | 0.896 |
Note: For HSBM benchmarks, our flat optimizer was configured to find the deepest community level, achieving competitive NMI even without a complex stratification loop.
2. Balancedness and Cost on SBM (Biased, N=512)#
We measured the balance indices ($B_{size}, B_{vol}, B_{dep}$) and cost metrics. Lower is better for all metrics.
| Method | $B_{size}$ | $B_{vol}$ | $B_{dep}$ | cost(Das) | cost(SE) |
|---|---|---|---|---|---|
| AL | 0.663 | 0.702 | 8.70 | 1.51E7 | 8.75E5 |
| SL | 0.217 | 0.225 | 1.29 | 1.92E7 | 8.92E5 |
| CL | 0.954 | 0.963 | 55.4 | 1.63E7 | 8.64E5 |
| Linkage++ | 0.589 | 0.655 | 6.82 | 4.90E6 | 5.86E5 |
| HCSE (BBM) | 0.165 | 0.167 | 1.21 | 4.94E6 | 5.62E5 |
| Ours | 0.000 | 0.000 | 1.00 | - | 7.48E+00 |
Note: By treating SE minimization as a global problem, our method finds partitions that are perfectly balanced with respect to the ground-truth cliques, resulting in zero balance penalties and significantly lower structural entropy costs.
Our Critical Review#
The Good:
- Elegant Theory: Bridging the gap between information theory (Shannon coding) and combinatorial graph clustering is mathematically beautiful.
- Inherent Balance: Unlike Dasgupta’s cost, the logarithmic volume term naturally forces balanced clusters without needing explicit constraint hyperparameters.
- Hyperparameter-Free Non-Binary Clustering: The stretch-and-compress method and inflection point analysis allow the data to speak for itself when determining the number of hierarchies.
The Limitations:
- Greedy Vulnerability: While the framework is robust, the “stretch” step heavily relies on a greedy agglomerative heuristic. For large, noisy, or highly complex networks, greedy bottom-up approaches are notoriously susceptible to falling into local minima.
- Scale Invariance: As the authors note, the approximation guarantees depend on cardinality weights \(\ge 1\). If edge weights are continuous fractions, the \(\log\) term can become negative, breaking certain theoretical bounds.
Our Idea and Improvement to Beat It#
While HCSE represents a massive leap forward, its reliance on greedy agglomerative clustering leaves performance on the table. We are developing a new algorithm to consistently outperform HCSE by treating HD-SE minimization strictly as a global optimization problem.
Theoretical Foundation: NP-Hardness of HD-SE#
To justify the need for a global optimizer, we first formally proved that Unconstrained HD-SE Minimization is strictly NP-hard.
Our proof uses a reduction from the strongly NP-complete 3-PARTITION problem. We constructed a specialized graph gadget consisting of dense element cliques suspended in a uniformly weak background graph. We proved that for this specific topology:
- The optimal coding tree structure algebraically collapses to exactly depth 2.
- This collapse maps the High-Dimensional SE problem directly to 2-Dimensional SE.
- Minimizing this 2D entropy naturally forces a perfect volumetric balance across the clusters, which is mathematically equivalent to solving 3-PARTITION.
The Path Forward: Global Optimization#
Armed with the knowledge that HD-SE is NP-hard and greedy approaches will inevitably hit local optima, our strategy aims to bridge the gap between flat (2D) and hierarchical (HD) structural entropy dynamically.
We have implemented a Two-Phase Hybrid Optimizer that combines the topological robustness of Modularity with the information-theoretic precision of Structural Entropy.
- Phase 1: Topological Initialization (Modularity): Structural Entropy landscapes are often “rugged” with narrow local minima (resolution traps). To escape these, we first optimize for Modularity (\(\alpha=0.0\)). Modularity acts as a “smooth” surrogate objective that is exceptionally effective at identifying macro-scale community structures. By starting with a Modularity-optimal partition, we provide the SE optimizer with a strong, topologically-sound initialization.
- Phase 2: Information-Theoretic Refinement (Structural Entropy): In the second phase, we perform a constrained local-move search using Pure Structural Entropy (\(\alpha=1.0\)). Starting from the Phase 1 partition, the optimizer fine-tunes the cluster boundaries to minimize the uncertainty of random walks on the graph. This ensures that the final hierarchy is not just topologically dense, but information-theoretically optimal.
Our next-generation framework is theoretically and empirically designed to achieve lower HD-SE scores across standard benchmarks like Cora, Citeseer, and synthetic SBMs.
Q&A#
Q: Why is balance important in hierarchical clustering?
A: In the absence of a strong community structure (e.g., a completely random clique), we expect our organizational hierarchy to be balanced—much like a binary search tree or Huffman coding tree. Previous combinatorial cost functions output random, skewed (caterpillar) trees for cliques. HD-SE naturally rectifies this.
Q: If HCSE is so good, why do we need to beat it?
A: HCSE is essentially a greedy heuristic operating under a brilliant new cost function. Greedy algorithms make locally optimal choices. On graphs with thousands of nodes and noisy edges, these local choices compound, leading the algorithm away from the true global minimum of the structural entropy.
Q: Does your global optimizer still output non-binary trees?
A: Yes! Our global optimizer targets the exact same HD-SE cost function. By optimizing globally and applying a differentiable or annealing-based compression step, we can identify even cleaner, more accurate \(k\)-ary hierarchies.
Stay tuned for our upcoming code release and benchmark results!